













































Machine Learning Workflow | Process, Steps, and Examples
Learn the machine learning workflow in simple steps with easy examples. Understand the full process from data to model building and real world uses today easily.

What does it actually take to build a machine learning model that works in the real world?
It is not just about choosing the right algorithm or having large amounts of data—it is about following a structured process that connects every stage of model development in a meaningful way. That structured process is known as the machine learning workflow.
A well-defined ML workflow takes a project from raw, unstructured data to a fully functional, production-ready model. Each step, from data preparation to evaluation and deployment, plays a critical role in determining whether the model performs consistently in real-world conditions or fails after training.
What Is a Machine Learning Workflow?
A machine learning workflow is a structured, step-by-step process used to build, train, evaluate, and deploy machine learning models. It transforms raw data—whether structured or unstructured—into a functional model capable of making accurate predictions.


Think of it as a blueprint that keeps every stage of a machine learning project organized and aligned with the goal. Without a defined workflow, even high-quality data and advanced algorithms can lead to inconsistent or unreliable results.
A well-designed workflow ensures that each step, from data collection and preprocessing to model deployment and monitoring, is repeatable, scalable, and capable of delivering real business value.
Why You Need an ML Workflow
A machine learning project has many moving parts — data, algorithms, evaluation, and deployment — and without a defined workflow, any one of them can break the entire process.
A workflow brings structure to each stage, making the outcome predictable and the process repeatable. Skipping it doesn't save time; it creates problems that are harder to fix later.
1. Keeps the Process Consistent - A workflow ensures every ML project follows the same structured path from data to deployment. This consistency makes results reproducible and the process easier to improve over time.
2. Saves Time and Reduces Rework - When each step is clearly defined, less time is spent figuring out what comes next. Catching problems early in the workflow prevents costly fixes later.
3. Improves Model Quality - A structured workflow forces validation of data, testing of assumptions, and evaluation of performance at every stage. This leads to more accurate and reliable models in production.
4. Makes Collaboration Easier - A shared workflow ensures everyone understands their role and where their work fits in the bigger picture. It removes ambiguity and keeps projects moving without unnecessary back-and-forth.
5. Supports Scaling - A repeatable machine learning lifecycle means the same process can be applied to new problems without starting from scratch. It also makes automation and MLOps practices easier to implement as projects grow.
6. Reduces Risk in Production - A workflow that includes monitoring ensures a model doesn't quietly degrade after deployment. It provides a system to catch issues before they impact business decisions.
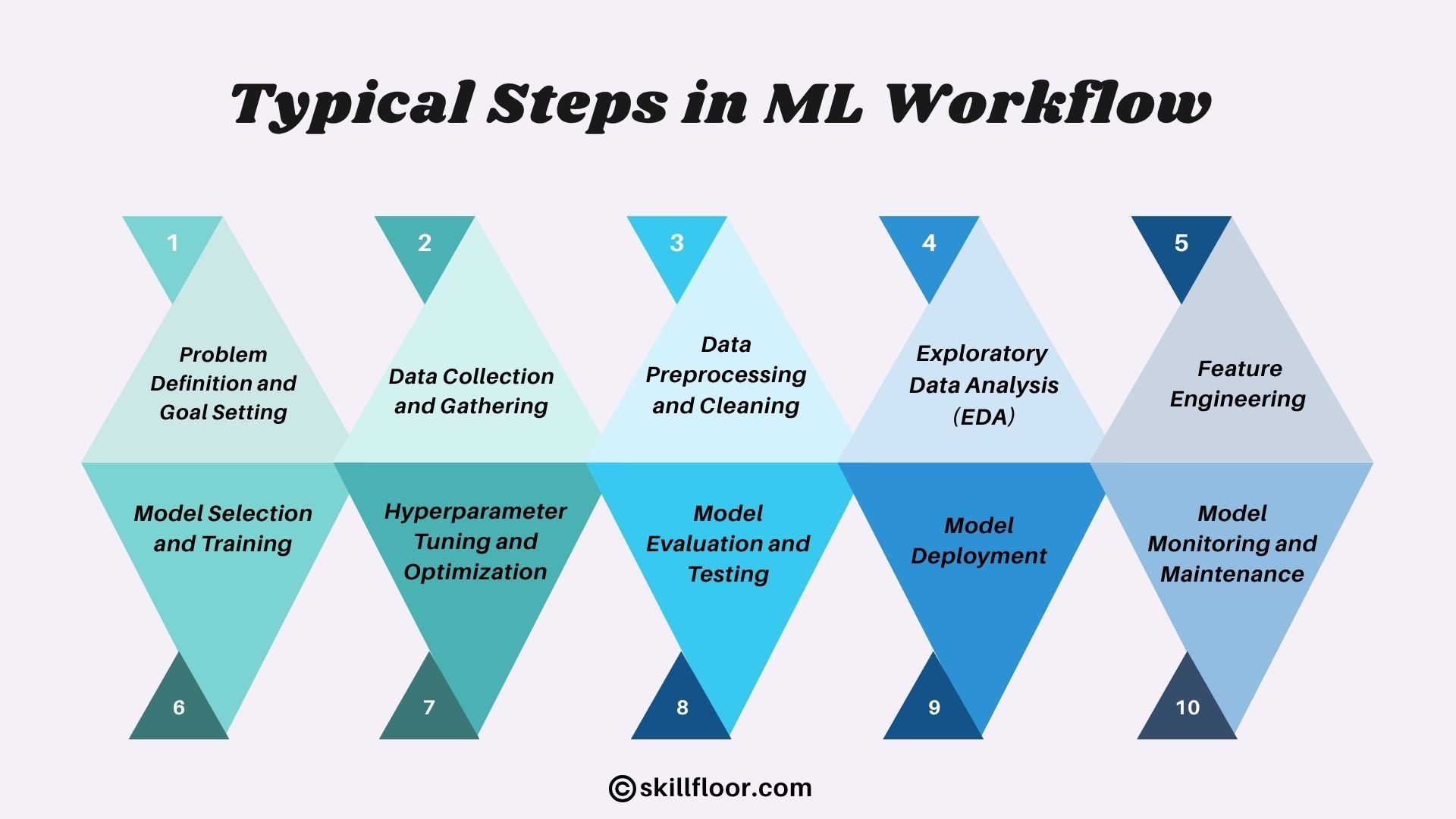
Typical Steps in ML Workflow
Every machine learning workflow follows a set of structured steps that work together toward one goal — a model that performs well in the real world. Understanding each step is key to executing the process effectively. Let's break them down.
1. Problem Definition and Goal Setting: Every ML project starts with defining what needs to be solved and how success will be measured. Without a clear problem statement, the entire workflow lacks direction.
-
Identifying the right business question ensures the model is built to deliver actual value, not just technical accuracy.
-
Setting measurable success metrics upfront, like accuracy thresholds or prediction speed, keeps the evaluation objective and focused.
2. Data Collection and Gathering: Data is the foundation of any ML project, and its quality directly determines how well the model performs. This step involves sourcing and consolidating data from all relevant inputs.
-
Data can come from internal databases, open-source datasets, APIs, or real-time streams, depending on the problem at hand.
-
The volume, variety, and reliability of collected data set the ceiling for everything the model can learn.
3. Data Preprocessing and Cleaning: Raw data is rarely ready to use; it needs to be cleaned, formatted, and structured before it can feed into an algorithm. This is often the most time-consuming step in the entire workflow.
-
Preprocessing involves handling missing values, removing duplicates, correcting errors, and standardizing formats.
-
Poorly cleaned data passed into a model produces inaccurate outputs, making this step non-negotiable.
4. Exploratory Data Analysis (EDA): Before building any model, the cleaned data must be explored to understand what it actually contains. EDA examines patterns, distributions, and relationships within the data to surface hidden issues early. Without this step, flawed assumptions carry silently into every decision that follows.
-
Distributions, histograms, and correlation matrices reveal skewness, outliers, and feature relationships, guiding every transformation and selection decision that follows.
-
Class imbalance checks and outlier detection ensure the data's underlying structure is fully understood before any feature or model decisions are made.
5. Feature Engineering: Feature engineering is the process of selecting and transforming raw variables into inputs that help the model learn better. It is where domain knowledge meets data science.
-
Relevant features are selected, irrelevant ones are dropped, and new features are sometimes created from existing data.
-
The quality of features chosen here directly impacts model accuracy more than the algorithm itself in many cases.



6. Model Selection and Training: This is where the algorithm is chosen, and the model begins learning patterns from the prepared data. Different problem types call for different algorithms.
-
The training set is fed into the chosen algorithm, which adjusts its internal parameters to minimize prediction errors.
-
Multiple algorithms are often tested and compared before settling on the one that performs best for the given problem.
7. Hyperparameter Tuning and Optimization: Once a model is trained, its internal settings that control how learning occurs still need to be adjusted to reach peak performance. Hyperparameter tuning is where those settings are systematically tested and refined across different configurations. Skipping this step means accepting a model that works but never reaches the accuracy it is actually capable of delivering.
-
Techniques like Grid Search, Random Search, and Bayesian Optimization systematically explore parameter combinations to find the optimal configuration.
-
Cross-validation during tuning ensures performance gains are genuine and not the result of overfitting to a specific data split.
8. Model Evaluation and Testing: Once trained, the model is tested on unseen data to measure how well it generalizes beyond what it learned. This step determines whether the model is ready for the real world.
-
Metrics like accuracy, precision, recall, and mean squared error are used depending on the type of problem being solved.
-
Poor evaluation results send the workflow back to earlier steps. This iterative loop is a normal part of the process.
9. Model Deployment: Deployment is the step where the trained model is made accessible for real-world use through APIs, applications, or cloud services. It marks the transition from experimentation to production.
-
The model is packaged and integrated into existing systems so end users or other applications can interact with it.
-
Deployment is not the finish line; it is the point where the model starts facing real data and real consequences.
10. Model Monitoring and Maintenance: After deployment, the model needs to be continuously observed to ensure it stays accurate over time. Data patterns change, and models that are not maintained will degrade silently.
-
Performance metrics are tracked regularly to detect any drift between what the model predicts and what actually happens.
-
When degradation is detected, the model is retrained or updated to bring it back to acceptable performance levels.
How ML Workflows Power Real-World Applications
Machine learning workflows are behind some of the most impactful technologies used today. Every intelligent system, whether it recommends a product, flags a fraudulent transaction, or predicts a diagnosis, is built on a structured workflow that makes it accurate and dependable.
|
Industry |
How ML Workflows Are Used |
Key Benefit |
|
Healthcare |
Analyze patient data to predict diagnoses, treatment outcomes, and disease progression |
Faster and more informed medical decisions |
|
E-Commerce |
Analyze user behavior to recommend relevant products and personalize the shopping experience |
Higher engagement and improved customer satisfaction |
|
Finance |
Detect fraudulent transactions in real time by identifying unusual patterns in spending behavior |
Reduced financial loss and improved customer security |
|
Marketing |
Predict customer behavior, segment audiences, and personalize campaigns based on historical data |
Higher conversion rates and efficient budget usage |
|
Manufacturing |
Analyze sensor data from machines to predict equipment failures before they occur |
Reduced downtime and lower maintenance costs |
|
Transportation |
Optimize routes, predict demand, and improve delivery efficiency using real-time data |
Faster and more efficient logistics operations |
Across every industry, the ML workflow is the engine behind the intelligence, ensuring that each application is built on clean data, well-trained models, and a process that can be trusted at scale.
Common Challenges in a Machine Learning Workflow
Building an effective machine learning workflow is rarely straightforward; every stage comes with its own set of obstacles that can slow progress or derail results entirely.
1. Poor Data Quality - Incomplete, inconsistent, or biased data directly leads to inaccurate model predictions and unreliable outcomes.
2. Overfitting - A model that performs well on training data but fails on new data has learned the noise rather than the actual pattern.
3. Feature Selection - Selecting irrelevant or excessive features adds noise to the model, making it harder to identify the patterns that actually matter.
4. High Computational Cost - Training complex models on large datasets demands significant time, memory, and processing power that can slow down the entire workflow.
5. Model Drift in Production - Real-world data changes over time, causing a deployed model's performance to silently degrade without proper monitoring in place.
Recognizing these challenges early and building safeguards into each step of the workflow is what separates a model that lasts from one that fails in production.
Best Practices to Improve Your ML Workflow
Following best practices does not just make the workflow smoother; it directly impacts the quality, reliability, and longevity of the models you build.
1. Start with a Clear Problem Statement - Before touching any data or ML algorithm, define exactly what the model needs to solve and how success will be measured. A vague problem leads to a directionless workflow and a model that delivers little real value.
2. Prioritize Data Quality Over Data Quantity - Clean, relevant, and well-structured data will always outperform a large dataset full of errors and inconsistencies. Investing time in data quality early saves significant rework in later stages of the workflow.
3. Document Every Step - Keep a clear record of data sources, preprocessing decisions, model versions, and evaluation results throughout the project. Good documentation makes the workflow reproducible and much easier to hand off or revisit later.
4. Treat the Workflow as Iterative, Not Linear - Expect to loop back to earlier steps when evaluation results are poor or new data reveals gaps. Iteration is not a sign of failure — it is how strong models are built.
5. Validating the Model Before and After Deployment - Testing the model on unseen data before deployment is necessary, but monitoring its performance after deployment is equally important. Real-world data behaves differently from training data, and ongoing validation keeps the model reliable.
6. Automate Repetitive Steps Where Possible - Tasks like data preprocessing, model retraining, and performance tracking can be automated to save time and reduce human error. Automation also makes the workflow easier to scale as projects grow in complexity.
Applying these practices consistently across every project is what separates a workflow that simply runs from one that consistently delivers results worth trusting.Institutes like Skillfloor help learners apply these best practices through hands-on projects and real-world ML training that builds practical, job-ready skills.
FAQs
1. What is the role of a machine learning workflow in a real-world project?
It acts as a blueprint that keeps every stage of the project organized, aligned, and moving toward a model that is accurate, reliable, and ready for production.
2. What makes a machine learning workflow repeatable and scalable?
A well-defined workflow with documented steps, automated processes, and consistent evaluation checkpoints makes it repeatable and scalable across new projects.
3. What is the most time-consuming step in an ML workflow?
Data preprocessing and cleaning are the most time-consuming steps due to the effort required to fix missing values, duplicates, and inconsistencies in raw data.
4. What happens when a model performs poorly during evaluation?
Poor evaluation results send the workflow back to earlier steps, like feature engineering or data preprocessing, to identify and fix the root cause.
5. Does an ML workflow end at deployment?
No, deployment is not the finish line, as the model must be continuously monitored and retrained whenever performance degradation is detected in production.
A machine learning workflow is the foundation that determines whether an ML project succeeds or falls apart. From defining the problem to monitoring the model in production, every step plays a specific role in delivering a result that is accurate, reliable, and built to last. Whether you are building your first model or refining an existing one, following a structured workflow is what separates experiments from solutions that actually work. Master the process, and the results will follow.












