













































Python for Machine Learning
Learn machine learning with Python! Discover easy tools to build models and improve industries like healthcare, finance, and more. Don’t miss out!

Every day, machine learning improves our digital lives by being present in everything from spam filters to Netflix recommendations. Python is the ideal language for anyone who wants to learn more about this fascinating area. It is filled with useful features to get you started quickly, powerful, and easy to understand.
Python is widely used in machine learning because of its ease of use and robust libraries, such as Scikit-learn and TensorFlow. Professionals and beginners alike may create models more easily with these expertly designed-tools. Top firms like Google and Facebook trust machine learning in Python, making it the preferred language for innovation.
The use of trustworthy tools is crucial while studying machine learning. Because of the size of the Python community, you can always get help, guides, and answers. Because it's open-source, you can also examine the code to make sure it's reliable and transparent. The tools in Python are reliable, well-maintained, and always evolving.
What Is Machine Learning?
Computers can now learn from data and experience by using a technique called machine learning. As robots digest more data, they become more proficient at seeing patterns and making better judgments over time, rather than adhering to rigid programming rules.


Big businesses all throughout the world, from healthcare to banking, employ machine learning to increase productivity and quality of service. It enables everything from fraud detection in banking to Netflix's tailored suggestions. Experts trust it, and it's becoming a vital tool for resolving practical issues in a variety of businesses.
Types of Machine Learning
1. Supervised Learning
The model is trained on labeled data—where the right answers are given—in supervised learning. It assists the system in making predictions, such as determining if an email is spam or not.
2. Unsupervised Learning
Labelless data is the subject of unsupervised learning. The algorithm discovers hidden patterns or clusters, such as classifying clients according to their past purchases without knowing their precise classifications beforehand.
3. Semi-Supervised Learning
Labeled and unlabeled data are combined in semi-supervised learning. It helps the algorithm learn more efficiently by utilizing the existing labeled data, which is useful when classifying data is costly or time-consuming.
4. Reinforcement Learning
An agent learns through trial and error in reinforcement learning. Like teaching a robot to navigate a maze, it learns from its actions and gets rewarded or penalized as it progresses.
Impact of Machine Learning in Today’s World
-
Healthcare Advancements: Faster analysis of medical data by physicians with machine learning results in better treatment plans and faster diagnoses, which ultimately improve patient outcomes.
-
Personalized Experiences: Machine learning produces personalized experiences that make our interactions with applications and websites better suited to our requirements, from personalized playlists to purchasing recommendations.
-
Fraud Detection: Banks increase security and reduce financial losses for both businesses and customers by using machine learning to identify fraudulent transactions in real time.
-
Smart Cities: Machine learning enhances municipal services, such as energy use and traffic control, making urban living more sustainable and effective for everybody.
-
Job Opportunities: There is an increasing need for qualified workers as more sectors use machine learning. Exciting employment opportunities may arise from acquiring a Certified Machine Learning Specialist certification.
-
Autonomous Vehicles: Self-driving vehicles are powered by machine learning, which enables them to learn from their surroundings and make better driving choices, opening the door to safer roads in the future.
Why Python is the preferred language for machine learning
Python is one of the most popular languages for machine learning and for a good reason. Here are a few things that make Python great for machine learning:
1. Simple Syntax
Beginners may easily begin machine learning in Python thanks to its straightforward and easy-to-understand syntax. It speeds up your learning process by enabling you to produce clear, simple code.
2. Powerful Libraries
Complex problems in machine learning in Python are made simpler by packages like Scikit-learn, TensorFlow, and Keras. By managing data processing, model construction, and training, these libraries lessen the need for human coding.
3. Large Community Support
When dealing with machine learning, Python's large developer and data scientist community makes it simpler to get tools, guides, and help. This community-based method improves education.
4. Wide Adoption in Industry
Python is used for machine learning by big tech organizations like Google and Facebook. With constant advancements and practical uses, machine learning in Python is guaranteed to stay relevant thanks to the widespread industry backing.
5. Versatility Across Platforms
Because Python is platform-independent, it may be used to create machine-learning models on any operating system. Because of its adaptability, it's the ideal option for deploying models in various situations.


6. Integration with Other Tools
Python is perfect for machine learning in Python projects that need smooth communication between many tools and systems since it interacts effectively with other databases and computer languages, such as SQL and R.
Understanding the Machine Learning Workflow
1. Define the Problem
The first step is to specify the issue you are attempting to resolve. Knowing the type of task will direct your whole workflow, whether it's a clustering, regression, or classification challenge.
2. Collect and Prepare Data
After identifying the issue, the following stage is to gather pertinent information. Obtaining raw data, cleaning it (removing missing or outlier numbers), and converting it into an analysis-ready format are all part of this process.
3. Choose the Right Model
Selecting the right machine learning model depends on the kind of issue you're trying to solve (classification, regression, etc.). From straightforward methods like linear regression to intricate models like neural networks, this might be the case.
4. Train the Model
The act of giving the model your data and modifying its internal parameters to enable it to provide precise predictions is known as training. During this stage, the model "learns" patterns from the training data.
5. Evaluate the Model
After training, assess the model's performance using the test set, which is unseen data. Accuracy, precision, recall, and F1 score for classification issues or mean squared error for regression are examples of common assessment measures.
6. Deploy the Model
The model is prepared for deployment once it operates effectively. In order for the model to forecast newly produced data, it must be integrated into a real-world setting.
Step-by-Step Guide to Building a Simple Machine Learning Model in Python
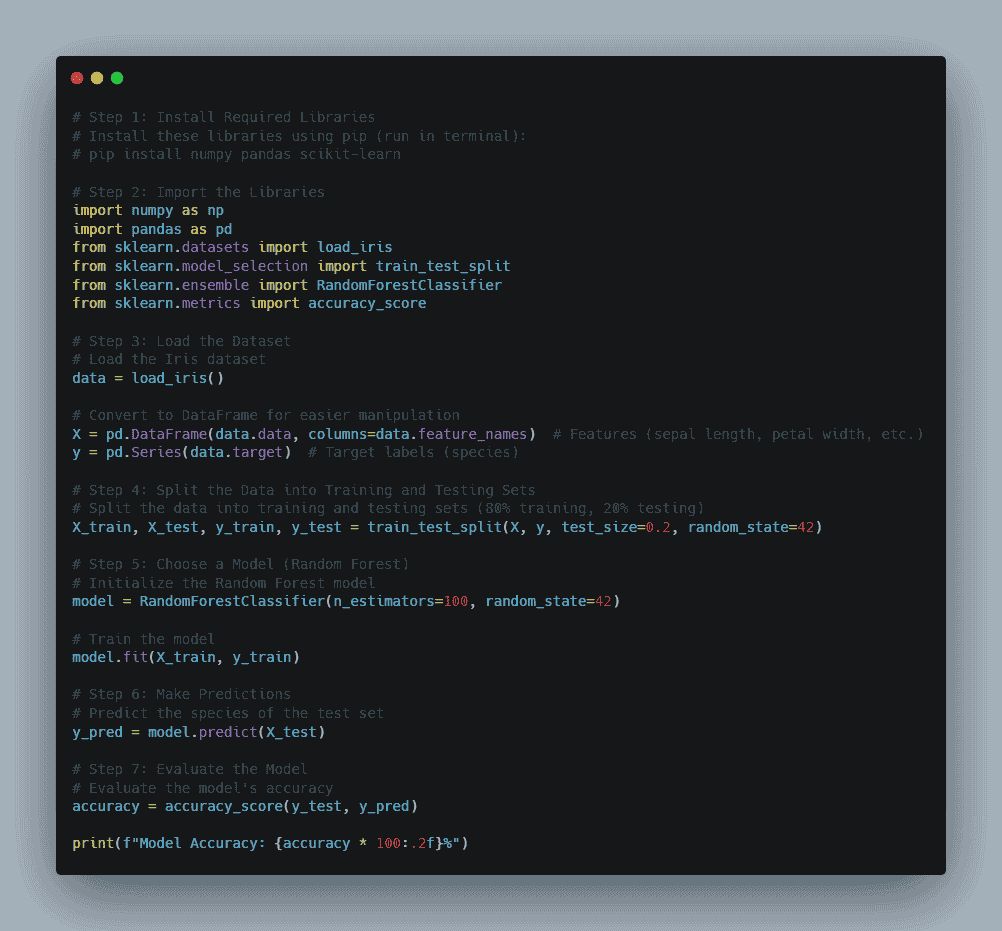
1. Install Python Libraries
Installing a few prerequisite libraries, such as NumPy, Pandas, and Scikit-learn, is necessary before you can begin working with machine learning in Python. You may manage data and create models with the aid of these tools.
2. Import Libraries and Load Data
You may import the required libraries into your Python environment after installing them. In order to manage data and build precise models, these libraries are essential for machine learning in Python.
3. Load and Explore the Data
The Iris dataset, a well-liked dataset for classification problems, will be loaded for this example. You may begin developing your model after importing the data and using machine learning in Python.
4. Split the Data
After that, divide the data into sets for testing and training. This stage makes it possible to test your model on fresh data. Using a suitable dataset split is crucial for performance, even if Python is one of the top machine-learning languages.

5. Choose a Model
The Random Forest model is a strong and adaptable algorithm that you will choose here. It is perfect for machine learning in Python as it is frequently used for classification tasks like species prediction in the Iris dataset.
6. Make Predictions
Making predictions is the next step once the model has been trained. By using their characteristics to predict the species of the test flowers, the model will show how machine learning in Python can be used for practical purposes.
7. Evaluate the Model
Lastly, by contrasting the model's predictions with the actual outcomes, you will assess how well your model worked. You may evaluate the precision and potency of your Python machine-learning model by doing this.
Model Evaluation and Hyperparameter Tuning in Machine Learning
1. Model Evaluation: Understanding Model Performance
To find out how effectively your machine learning model generalizes to new data, you must evaluate it. Common measures that shed light on model behavior include accuracy, precision, recall, and cross-validation.
a. Accuracy Score
Accuracy quantifies the proportion of accurate forecasts. Although this measure performs well in datasets that are balanced, it might not accurately represent performance in situations such as Python machine learning for unbalanced data.
b. Confusion Matrix
A more detailed picture is offered by a confusion matrix, which shows true positives, false positives, true negatives, and false negatives. It is beneficial to comprehend the particular kinds of mistakes that your Python machine learning model does.
c. Precision, Recall, and F1-Score
Working with unbalanced data requires a high level of precision, recall, and F1-score. Compared to accuracy, they give a more thorough performance review, providing greater insight into how the model manages minority classes.
d. Cross-Validation
One method for evaluating how well your model performs on various data subsets is cross-validation. In risk management, it lowers the possibility of overfitting and provides a more accurate performance metric.
2. Hyperparameter Tuning: Improving Model Performance
Machine learning in Python includes hyperparameter adjustment as a crucial step. Model accuracy may be greatly increased by fine-tuning hyperparameters such as the learning rate or the number of trees in a random forest.
a. Grid Search
Grid search is a technique that thoroughly examines every potential combination of hyperparameters from a predetermined list. Despite being successful, this method can be computationally costly, particularly when working with big datasets in Python machine learning.
b. Randomized Search
Because it samples hyperparameters at random, randomized search is quicker and more effective than grid search. When working with vast parameter spaces in machine learning in Python, it is very helpful.
c. Bayesian Optimization
By utilizing a probabilistic model to intelligently explore the hyperparameter space, Bayesian optimization drastically lowers the number of trials required. It's a sophisticated technique that frequently yields greater outcomes in less time.
3. Model Comparison: Choosing the Best Model
To select the best model, you must compare the performance of each one after evaluating them. When choosing a model, take into account aspects such as interpretability, speed, and accuracy.
a. Multiple Model Evaluation
The optimal model may be found by evaluating several models, such as Random Forest, SVM, or Decision Trees. A more thorough understanding of each model's advantages may be obtained by comparing measures such as accuracy, precision, and recall.
b. Trade-offs Between Models
Every model has compromises. One model could be more accurate, while another might be quicker or easier to understand. These considerations must be balanced, particularly when it comes to machine learning in Python programs for practical applications.
The Future of Machine Learning
The future of machine learning looks incredibly promising, with rapid advancements in algorithms, hardware, and data processing. Machine learning models will advance in accuracy, efficiency, and accessibility, revolutionizing sectors like healthcare, banking, and transportation in ways we can't yet fully comprehend.
Machine learning will develop further in the upcoming years, allowing for more individualized user experiences and task automation in a variety of industries. Machine learning will become more potent and widespread with advancements like edge computing and expanded cloud infrastructure, enabling both individuals and enterprises to seize new possibilities and tackle challenging issues.
Machine learning has an indisputable influence on our daily lives as technology advances. By offering creative answers to challenging issues, it is transforming a variety of industries, including healthcare and finance. Python and other tools have made machine learning more approachable, allowing both novices and experts to explore this fascinating topic. Because of the ongoing improvements in processing power and techniques, machine learning in Python has a bright future. The potential for development and innovation will only increase as more sectors use machine learning, making it an intriguing field to investigate.












