













































Introduction to Data Science Models
Discover how data science models work to find patterns, make predictions, and turn everyday data into insights that help in smarter decisions and problem solving.

Imagine your phone automatically tagging a friend in a picture or discovering a movie you like on Netflix. Behind the scenes, systems identify patterns and create predictions, which is why these things happen. One aspect of studying in a data science course is comprehending this.
Our daily routines, our buying preferences, and even the music we listen to are all surrounded by data. This data is merely information on its own. By displaying patterns, forecasting outcomes, or offering guidance, models assist in transforming it into something practical that helps us make better decisions in our day-to-day lives.
Think of a model as a recipe. Ingredients are combined, steps are followed, and a final dish is created. Better recipes result in better outcomes. Similarly, a model collects data, analyzes it, and generates insights that reveal trends or help solve problems.
What is Data Science?
The process of gathering, analyzing, and interpreting data to identify relevant trends and information is known as data science. By transforming raw data into insights, it assists individuals and businesses in making better decisions. Data science makes sense of the information we are surrounded by using straightforward techniques and tools.


In order to analyze information, data science integrates knowledge from several fields, including computers, statistics, and mathematics. In a wide range of industries, including business, education, and healthcare, it can forecast trends, resolve issues, and enhance decision-making. To make sense of common facts, anyone can begin learning it step-by-step.
The Role of Data Science in Modern Life
-
Improving Healthcare: Data science makes healthcare faster, more precise, and more personalized for everyone by assisting physicians in tracking patient health, predicting diseases, and suggesting treatments.
-
Enhancing Business Decisions: Businesses utilize data science to predict trends, comprehend consumer behavior, and make more informed decisions that increase customer pleasure, efficiency, and revenue.
-
Personalized Recommendations: Data science is used by services like Netflix and Spotify to make personalized movie, music, and product recommendations based on user interests, enhancing user experiences.
-
Financial Management: Data science is used by banks and other financial organizations to manage risks, identify fraud, and assist clients in making more informed financial decisions.
-
Transportation and Travel: Data science makes commuting quicker, safer, and more effective by managing public transportation, planning routes, and forecasting traffic.
-
Smart Cities and Environment: Cities can help build cleaner, smarter, and more sustainable communities by using data science to monitor energy, cut waste, and enhance safety.
What Are Data Science Models?
Data science models are tools that assist in interpreting data and making predictions. They analyze historical data to make informed forecasts about future events. These models are often used in the background for various applications, such as predicting the weather and recommending movies, among other uses.
The functions of various models vary. While some algorithms categorize things, like classifying emails into spam or inbox, others forecast figures, like property values. Additionally, some models combine related objects into one group. We can address issues and use data to make better judgments if we choose the appropriate model.
Understanding the Purpose of Data Science Models
-
Finding Patterns: Data science models make it easier to comprehend trends and linkages that are not immediately apparent by assisting us in uncovering hidden patterns in massive information sets.
-
Making Predictions: By analyzing historical data, models can predict future events, including sales, weather, and client preferences, helping in planning and preparedness.
-
Improving Decisions: Models help organizations and businesses make better decisions. By depending on insights derived from data, they decrease uncertainty and increase precision in routine decisions.
-
Saving Time and Effort: Data science models are capable of processing vast volumes of data rapidly; they can do tasks that would take humans hours or even days in a matter of seconds.
-
Personalizing Experiences: Through the creation of tailored recommendations, such as those for movies, music, or items, models contribute to the enjoyment and customization of digital experiences.
-
Solving Real Problems: Data science models are used to solve real-world problems, making life safer, simpler, and more effective—from identifying fraud to enhancing healthcare.
Different Types of Data Science Models
Different kinds of data science models are available, each intended to address a particular issue. While some models identify objects, others forecast numbers, and yet others discover hidden groups or gain experience. The most prevalent kinds will be examined.
1. Supervised Learning Models
Learning with an instructor is similar to supervised learning. In order to predict new and unknown outcomes, the model analyzes cases with responses, discovers patterns, and applies this information.
-
Regression Models: Based on data, these models predict numerical values. For example, calculating the cost of a home based on characteristics like location, number of rooms, and overall property size.
-
Classification Models: Data is sorted into groups by these models. For example, determining whether to put an incoming email in the main inbox or the spam folder.
Real-Life Example: Supervised learning models based on historical customer data are used by banks to determine if a loan applicant is likely to default or repay on time.
2. Unsupervised Learning Models
Learning without an instructor is known as unsupervised learning. Through independent data exploration, the model uncovers hidden patterns or groupings without predetermined solutions, broadening the application of data science to actual problem solving.
-
Clustering Models: Similar data points are grouped together using these models. For instance, companies can create more effective marketing campaigns and customized offers by grouping clients with comparable purchasing patterns.
-
Dimensionality Reduction Models: These models preserve crucial characteristics while streamlining big, complicated datasets. This facilitates information processing, visualization, and comprehension without sacrificing crucial insights.
Real-Life Example: Clustering methods are used by online retailers to identify consumer groups that have similar interests. They suggest goods that customers are more likely to like based on these data.
3. Semi-Supervised Learning Models
A combination of supervised and unsupervised techniques is called semi-supervised learning. To effectively learn, it combines a little amount of labeled data with a considerably greater amount of unlabeled data.
Real-Life Example: Labeling patient data is frequently costly and time-consuming in medical research. By integrating a large number of unlabeled records with a small number of labeled examples, semi-supervised models can train effectively while consuming less time and money.


4. Reinforcement Learning Models
By making choices and getting feedback, a model learns through trial and error in reinforcement learning. Mistakes result in consequences, but smart decisions yield rewards. This method gradually enables the model to become better and automatically make wiser decisions.
Real-Life Example: Reinforcement learning is exemplified by self-driving automobiles. To determine whether to accelerate, stop, or turn, they rely on sensors and input. Over time, the system learns safe and effective driving practices by making these choices repeatedly.
5. Deep Learning Models
Artificial neural networks, which analyze layers of data like the human brain, are used in deep learning. These models are utilized extensively in computer vision applications nowadays because of their strength in processing unstructured input, including text, audio, and images.
Real-Life Example: Deep learning is essential to voice assistants like Siri and Alexa, as well as facial recognition on smartphones. These models make ordinary digital interactions more natural, quicker, and far more intelligent for people worldwide by analyzing faces, recognizing voices, and comprehending speech patterns.
6. Ensemble Models
The accuracy and dependability of ensemble models are increased by combining the advantages of several models. Instead of relying on just one model, they combine multiple models, which improves forecasts and lowers mistakes for a wide range of data and issues.
Real-Life Example: Ensemble models are commonly employed in weather prediction. By combining the outputs of various forecasting models, meteorologists can produce more accurate and reliable forecasts. This approach reduces uncertainty and helps communities better prepare for natural disasters and changing weather patterns.
How Data Science Models Works
1. Collecting Data
The first step for models is to collect data from multiple sources, including databases, sensors, and internet platforms. Good data collection is crucial since it serves as the basis for identifying trends and producing precise forecasts.
Insufficient data may cause models to overlook significant patterns or make inaccurate assumptions. By meticulously gathering data, we make sure the model has enough examples to discover important relationships and produce practical insights for practical uses.
2. Cleaning Data
Raw data might be confusing to a model since it frequently contains mistakes, duplication, or missing variables. A thorough data cleaning process helps guarantee that the data is reliable, consistent, and prepared for modeling or analysis.
Standardizing formats and eliminating unnecessary information are further steps in data cleaning. This stage guarantees that insights produced are trustworthy and helpful for making decisions, enhances prediction quality, and avoids errors during model training.
3. Training the Model
The model learns patterns and correlations between input features and results by analyzing historical data during training. This aids in the model's comprehension of how to forecast fresh, untested data.
Because training is iterative, the model makes adjustments to itself several times in order to reduce errors. Its forecasts for real-world issues get more precise and dependable the more it learns throughout this stage.
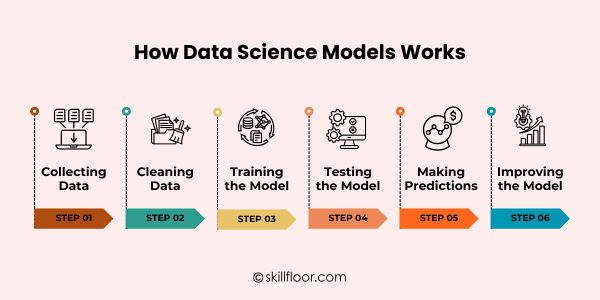
4. Testing the Model
The model is tested on new, untested data after training. This aids in determining whether it can apply what it has learned to other contexts and generate precise predictions.
Experiments also reveal model flaws like overfitting or underfitting. The model can be improved for greater accuracy and dependability by developers by examining performance during testing.
5. Making Predictions
The model can categorize new data or forecast results after it has been trained and evaluated. Predictions support decision-making in a variety of industries and are based on the patterns discovered during training.
A model might predict home values, consumer preferences, or equipment malfunctions, for instance. Precise forecasts help people and companies make better decisions, save time, and lower risks.
6. Improving the Model
Models may constantly be improved by experimenting with other methods, changing parameters, or adding more data. The model will improve in accuracy, adaptability, and efficacy over time if the prerequisites, such as high-quality data, appropriate characteristics, and well-defined goals, are understood.
The process of improvement is continuous. Performance is maintained at a high level by prediction monitoring, error-learning, and model updating with fresh data or methods, which makes the model dependable and practical for real-world tasks and changing requirements.
Techniques for Evaluating Data Science Models
-
Train-Test Split: Data is separated into training and testing sets using this method. The testing set is used to assess the model's ability to predict fresh, unseen data after it has been trained on the training set.
-
Cross-Validation: The model is trained and evaluated on each of the several folds of data that are separated. This guarantees uniformity, lessens prejudice, and demonstrates the model's dependability across various data sets.
-
Confusion Matrix: It displays true positives, false positives, true negatives, and false negatives, and is frequently used in classification models. This makes it easier to see the model's strengths and weaknesses.
-
Accuracy, Precision, and Recall: Recall quantifies detected positives, precision indicates accurate positive predictions, and accuracy gauges total correctness. When combined, these measures provide a thorough assessment of categorization performance.
-
Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE): These measures, which are used in regression models, quantify the variation between expected and actual values in order to assess prediction accuracy.
-
ROC Curve and AUC: AUC gauges the overall performance of the model, particularly in classification tasks, while the Receiver Operating Characteristic curve displays the trade-off between true positive and false positive rates.
How to Choose the Right Data Science Model
-
Understand the Problem: Decide what kind of issue you wish to resolve. Is it identifying patterns, categorizing objects, or forecasting numbers? Knowing this makes it easier to choose the right model kinds.
-
Analyze Your Data: Take a look at your data. Verify its format, size, and quality. While some models are better at handling tiny or unstructured data, others do better with larger datasets.
-
Consider Accuracy and Performance: Determine which models offer the most accurate forecasts. While complicated models may increase accuracy but demand more resources, simpler models may be less accurate.
-
Think About Interpretability: While some models, like deep learning, are more complicated, others, like decision trees, are simple to comprehend. Decide if you require concise explanations of the outcomes.
-
Assess Resources: Think about the time, skill, and processing power needed. While simpler models can operate on basic platforms, others require sophisticated abilities or a lot of processing power.
-
Test and Compare Models: Comparing the performance of several models is often helpful. To determine which model is most effective for your particular data and issue, use metrics, cross-validation, and experiments.
Real-World Applications of Data Science
-
Healthcare: Physicians may predict illnesses, recommend treatments, and keep an eye on patients' health with the use of data science. Models are used by hospitals to enhance the quality of care and provide more individualized, expedited healthcare services.
-
Finance: Data science is used by banks and other financial institutions to identify fraud, control risks, and help consumers make better financial decisions, safeguarding both their companies and their customers.
-
Retail and E-commerce: Businesses examine consumer preferences, shopping habits, and behavior. This enhances consumer satisfaction and sales by enabling tailored advice, focused marketing, and improved inventory management.
-
Transportation: Traffic prediction, route optimization, and effective public transportation management are all made possible by data science. This makes everyone's commute safer and quicker while also cutting down on delays and fuel use.
-
Marketing and Sales: Companies utilize data science to gauge the success of campaigns, forecast trends, and comprehend consumer preferences. This guarantees more successful and targeted marketing campaigns.
-
Smart Cities and Environment: Data science is used by cities to track energy use, cut waste, and enhance security. It is in favor of making urban areas safer, cleaner, and more sustainable for citizens.
Future Trends in Data Science
More sectors are depending on data science to make better decisions, which bodes well for the field's future. Automation, real-time forecasting, and advanced analytics will all keep expanding. Businesses and individuals may better grasp how machines might handle data to increase accuracy, efficiency, and productivity in daily tasks by learning about data science in AI.
Other emerging trends include explainable models, edge computing, and data privacy. Organizations will prioritize openness and the ethical use of data. Furthermore, merging data from many sources will produce deeper insights, accelerating and improving decision-making in the financial, healthcare, and other sectors.
Data science models play a significant role in our daily lives, helping us understand the world and make better decisions. These algorithms transform raw data into valuable insights that can improve healthcare and predict business trends. By grasping how these models operate—starting from data collection to outcome forecasting—we unlock numerous opportunities for effective problem-solving. As more companies adopt data-driven strategies, the ability to understand and utilize these models becomes increasingly important. Anyone can begin using these models by gradually learning about the different types and their functions. With practice and curiosity, data science models can enhance everyday tasks by revealing patterns, saving time, and improving decision-making across various aspects of life.












