













































Beginner’s Guide to Data Cleaning in Data Science
Learn data cleaning in data science with easy steps. Fix errors, handle missing values, remove duplicates, and prepare datasets for accurate, reliable analysis.

In data science, the quality of your data can make a huge difference in your results. Data directly from the source is frequently jumbled, containing errors, missing details, and inconsistencies. This explains the significance of data cleaning. Data cleaning, sometimes known as scrubbing or data cleansing, is the initial stage of ensuring that your dataset is accurate, well-structured, and usable.
If you skip this step, your analysis may yield inaccurate insights that could result in poor choices. Cleaning your data makes it easier to identify errors, add missing details, get rid of duplicates, and ensure consistency. You may have confidence in your findings and make more informed judgments by taking the time to thoroughly clean your data.
What is Data Cleaning?
The process of identifying and correcting errors, discrepancies, or missing data in a dataset to make it reliable and accurate is known as data cleaning. It makes it easier to guarantee that the information you use for analysis is trustworthy and relevant.
-
Removing duplicate or unnecessary records

-
Fixing structural or formatting errors
-
Filling in or handling missing values
-
Identifying and managing outliers
-
Standardizing formats for dates, text, or numbers
-
Correcting typos or inconsistencies


This procedure is essential to ensuring that your analysis provides the appropriate insights and facilitates improved decision-making.
It helps to have a basic understanding of data science tools and processes before delving deeper. You'll probably become familiar with Python, Pandas, NumPy, SQL databases, and data visualization programs like Tableau or Power BI if you're enrolled in a data science course. It will be a lot simpler to understand and use data cleansing strategies if you possess these abilities.
The Importance of Data Cleaning in Data Science
-
Ensures Accurate Results: Errors in analysis can be avoided with clean data, resulting in accurate and trustworthy conclusions that support better business, research, or data-driven project decisions.
-
Removes Duplicates and Redundancy: You can reduce storage space, streamline analysis, and prevent inaccurate findings from counting the same data repeatedly by eliminating redundant or superfluous information.
-
Handles Missing Information: Cleaning makes your analysis more thorough and reliable by helping in the identification of gaps or missing values in your dataset and offering solutions for managing or filling them.
-
Improves Data Consistency: Your dataset becomes consistent when formats are standardized, mistakes are fixed, and categories are aligned, making it simpler to comprehend and compare results from various data sources.
-
Reduces Errors in Models: Clean data improves the performance of statistical or machine learning models. Your forecasts and insights will be more accurate if you eliminate errors and outliers.
-
Saves Time and Effort Later: By taking the time to clean the data at the beginning, problems can be avoided later. Particularly for big datasets or complex projects, it speeds up, simplifies, and lessens the difficulty of future research.
Step-by-Step Data Cleaning Process
1. Understand Your Data
Take some time to explore your dataset and learn about its contents before cleaning. Comprehending the data facilitates the identification of issues, the recognition of trends, and the efficient planning of the cleaning procedure.
-
Explore the Dataset: To have a clear understanding of the structure and type of information contained in your data, look at the first few rows, column names, and data types.
-
Check Summary Statistics: Examine fundamental statistics such as counts, minimums, maximums, and averages to identify odd numbers, missing information, or discrepancies that require attention during cleaning.
2. Backup Raw Data
Make sure you have a backup of your original dataset before beginning any cleaning procedures. If you make mistakes, this helps safeguard your source data in data science.
-
Save a Copy: If something goes wrong during cleaning, you can always go back to your raw data by storing it in a secure folder or drive.
-
Work on a Duplicate: Make modifications only to a duplicate of your dataset. This guarantees that you don't inadvertently lose any crucial information and preserves your original data.
3. Explore Data Initially
Take some time to explore your data before you begin cleaning. You can identify any issues early on and gain a better understanding of the situation with this first look.
-
View Sample Records: Examine the first few rows of your dataset to get a sense of how it appears, look for any blank spaces, or identify any unusual or noteworthy numbers.
-
Understand Data Types: Examine each column to see if it has dates, text, or numbers in it. This helps in your planning for properly cleaning and organizing your data.
4. Check Data Types


Checking each column's data type is crucial after examining your data. This assists you in ensuring that the format of your dataset is appropriate for precise analysis.
-
Review Each Column: Determine if the information is saved as dates, numbers, or text. Errors in computations or visualizations might result from using the incorrect data types.
-
Fix Mismatched Types: Change date formats or convert text numbers to numeric values so that your data is compatible with analytic tools and techniques.
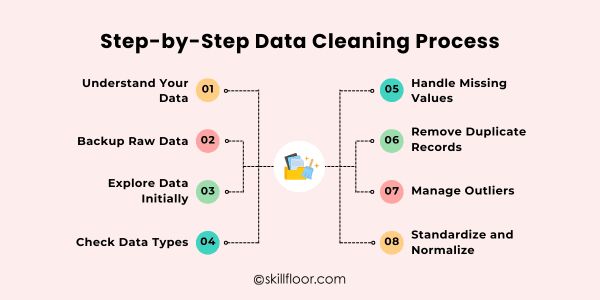
5. Handle Missing Values
Missing values can impact the accuracy of your results and are prevalent in most datasets. It's critical to locate and manage them prior to beginning your data analysis.
-
Identify Missing Data: Examine your dataset for null values or empty cells. You can choose the appropriate course of action to address missing data by knowing where it is.
-
Decide How to Handle: If there are too many missing values, you can eliminate rows or replace them with averages, medians, or most common values.
6. Remove Duplicate Records
Duplicate records have the potential to distort your findings and complicate your study. Finding and eliminating them guarantees the accuracy and dependability of your dataset. This procedure can be appropriately guided by adhering to the principles of data science.
-
Find Duplicates: Look for rows with the same values in important columns. Summaries and calculations may be impacted by these recurring records, which may also undermine your analysis.
-
Remove Carefully: To ensure that you don't inadvertently erase crucial or distinctive information, delete duplicates only after evaluating them.
7. Manage Outliers
Values that deviate significantly from the rest of your data are called outliers. It's critical to recognize and manage them carefully because they can have an impact on averages, trends, and forecasts.
-
Identify Unusual Values: To identify outliers in your dataset, use straightforward charts such as boxplots or search for numbers that deviate significantly from the norm.
-
Decide How to Handle: Outliers can be eliminated, modified, or retained if they accurately reflect actual circumstances. Before making any modifications, always take the context into account.
8. Standardize and Normalize
Your data will be more consistent and simpler to examine if you standardize and normalize it. When working with numbers that have drastically differing scales, this step is highly essential.
-
Standardize Values: Modify the data to conform to a standard scale or format, such as making all dates the same style or all text lowercase.
-
Normalize Numbers: Adjust numerical numbers to fall inside a range, often 0 to 1, to improve the accuracy and significance of computations and comparisons.
Data Cleaning in Data Science: Building Reliable Insights
In data science, trustworthy insights are built on clean data. You can make sure your analysis is reliable and accurate by eliminating duplicates, addressing missing values, correcting errors, and standardizing formats. You can identify real trends in your data, create stronger models, and make better decisions with clean datasets. Every project benefits from taking the time to properly clean data since it saves effort and produces better outcomes.
Common Data Issues
-
Missing Data: Errors or insufficient analysis may result from missing values. Proper handling of them guarantees precise insights and avoids errors when creating dashboards or reports.
-
Duplicate Data: Results and summary can be distorted by duplicate records. Eliminating them preserves the correctness of your dataset while keeping it dependable, tidy, and prepared for proper analysis.
-
Inconsistent Formatting: Analyses may become confused by disparate forms for numbers, text, or dates. Standardizing these guarantees consistency and facilitates effective dataset interpretation or merging.
-
Typos and Spelling Errors: Typographical errors or misspellings in text columns might result in superfluous categories. Fixing them guarantees lucidity, minimizes mistakes, and enhances the caliber of your discoveries.
-
Outliers: Unusual values known as outliers have the potential to distort outcomes. It's critical to recognize and properly deal with them, particularly when training data science models to guarantee precise predictions.
-
Data Type Mismatches: Errors may arise from data types that are incorrect, such as text numbers. By fixing them, calculations, visualizations, and analysis will all function without hiccups.
Effective data cleansing begins with an understanding of common data problems. Data scientists can provide solutions to issues while preserving the integrity of datasets by being aware of them. Using technical expertise and subject knowledge to properly handle these problems without making new mistakes or prejudices is the real challenge.
Essential Data Cleaning Techniques & Tools
Techniques
1. Removing Duplicates
Eliminating duplicates guarantees the accuracy and cleanliness of your dataset. Finding and removing repetitive records is crucial for accurate findings because they can skew analysis, reports, and insights.
-
Find duplicates in crucial columns to prevent inadvertently deleting valuable records.
-
Find and mark repeated rows fast with Excel or Python methods.
-
Verify duplicates twice to avoid unintentionally losing important data.
-
A copy of your original data should always be saved before eliminating duplicates.
2. Handling Missing Values
Your dataset will be of higher quality if you handle missing values. Incomplete rows can be removed or gaps filled to avoid mistakes and guarantee that your analysis yields reliable, significant results.
-
Look for null or empty values in your dataset that require attention.
-
Depending on the context, choose whether to eliminate incomplete rows or fill in missing data.
-
To preserve accuracy, substitute medians or averages for missing numerical values.
-
For transparency, document the process used to handle missing values.
3. Correcting Inconsistencies
Your dataset becomes consistent when discrepancies are fixed. Your study will remain reliable as well as easy to understand if you standardize wording, dates, and forms to maintain clarity and minimize errors.
-
To make analysis simpler, convert all date formats to a common format.
-
Make sure that all of the terminology, capitalization, and spelling in the text columns are consistent.
-
To ensure that related items are classified consistently throughout the collection, align the categories.
-
Ensure that the decimal or thousand separators used in numerical data are the same.
4. Managing Outliers
By controlling outliers, you can avoid having your analysis distorted by odd values. More accurate results and more reliable insights are guaranteed when extreme values are recognized and handled appropriately.
-
To identify values that substantially depart from the norm, use charts or statistical techniques.
-
Before acting, ascertain whether outliers are errors or valid data points.
-
Outliers can be eliminated, modified, or retained depending on how they affect the analysis's findings.
-
To keep your dataset cleaning procedure transparent, take note of how outliers were handled.
Tools
-
Python (Pandas & NumPy): Python packages like Pandas and NumPy facilitate the handling of missing values, duplication removal, outlier management, and effective dataset standardization for precise analysis.
-
Excel / Google Sheets: With features to filter data, identify duplicates, correct basic errors, and act as rudimentary data cleaning tools, Excel and Google Sheets are ideal for novices or small datasets.
-
OpenRefine: With the help of OpenRefine, you can standardize formats, clean up disorganized datasets, fix errors, and turn unstructured data into information that is suitable for analysis.
-
Trifacta Wrangler: A simple-to-use tool, Trifacta Wrangler aids in the rapid preparation, transformation, and cleaning of data. Repetitive activities are made simpler, and datasets are prepared for effective analysis.
Best Practices in Data Cleaning
-
Know Your Data: Examine your dataset for a while before making any modifications. You may identify mistakes and create the best cleaning plan by being aware of column meanings, data kinds, and common trends.
-
Keep Raw Copies: Keep an unaltered copy of your original dataset at all times. This guarantees that in the event that errors arise or you need to begin cleaning again, you may go back to the raw data.
-
Document Your Steps: Every modification you make when cleansing data should be documented. Documentation guarantees transparency, makes it easier to track changes, and makes your process understandable to others.
-
Start with Samples: Start by testing cleaning techniques on a small subset of your dataset. This enables you to check methods, identify unforeseen problems, and avoid errors on the entire dataset.
-
Automate Cleaning Tasks: Use tools or scripts to automate routine cleaning operations, such as standardizing formats, filling in missing entries, and eliminating duplicates. Human error is decreased and time is saved by automation.
-
Validate Regularly: Verify your data to make sure the corrections are right after cleaning. Validation guarantees accuracy, consistency, and completeness, ensuring that your dataset is trustworthy for reporting or analysis.
No successful data project can be completed without effective data cleaning. By taking the time to examine your data, address missing values, remove duplicates, correct inconsistencies, and manage outliers, you can ensure that your analysis is accurate and trustworthy. Clean data not only enhances the reliability of your insights but also saves time, reduces errors, and simplifies the handling of large datasets. Utilizing the right tools, following best practices, and understanding common data issues can help you transform messy datasets into valuable information that supports better decision-making. By investing effort into proper data cleaning in data science, you can increase your confidence in your findings and focus on identifying significant trends and patterns without worrying about mistakes or inconsistencies.












